Contrastive Multiple Correspondence Analysis (cMCA): Using Contrastive Learing to Identify Latent Groups in Political Parties
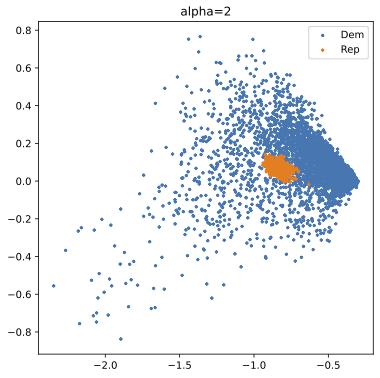
Scaling methods have long been utilized to simplify and cluster high-dimensional data. However, the general latent spaces across all predefined groups derived from these methods sometimes do not fall into researchers’ interest regarding specific patterns within groups. To tackle this issue, we adopt an emerging analysis approach called contrastive learning. We contribute to this growing field by extending its ideas to multiple correspondence analysis (MCA) in order to enable an analysis of data often encountered by social scientists—containing binary, ordinal, and nominal variables. We demonstrate the utility of contrastive MCA (cMCA) by analyzing two different surveys of voters in the U.S. and U.K. Our results suggest that, first, cMCA can identify substantively important dimensions and divisions among subgroups that are overlooked by traditional methods; second, for other cases, cMCA can derive latent traits that emphasize subgroups seen moderately in those derived by traditional methods.
Keywords: contrastive learning; scaling; multiple correspondence analysis; subgroup analysis; data mining
The paper can be downloaded here.
Data and replication codes could be reached here.
cmca module could be downloaded here.